sql что такое индексы какие они бывают
Основы индексов в Microsoft SQL Server
В данном материале будут рассмотрены такие объекты базы данных Microsoft SQL Server как индексы, Вы узнаете, что такое индексы, какие типы индексов бывают, как их создавать, оптимизировать и удалять.
Что такое индексы в базе данных?

Индекс — это объект базы данных, который представляет собой структуру данных, состоящую из ключей, построенных на основе одного или нескольких столбцов таблицы или представления, и указателей, которые сопоставляются с местом хранения заданных данных. Индексы предназначены для более быстрого получения строк из таблицы, другими словами, индексы обеспечивают быстрый поиск данных в таблице, что значительно повышает производительность запросов и приложений. Индексы также могут быть использованы и для обеспечения уникальности строк таблицы, гарантируя тем самым целостность данных.
Типы индексов в Microsoft SQL Server
В Microsoft SQL Server существуют следующие типы индексов:
Создание и удаление индексов в Microsoft SQL Server
Перед тем как приступать к созданию индекса его необходимо хорошо спроектировать, для того чтобы эффективно использовать этот индекс, так как плохо спроектированные индексы могут не увеличить производительность, а наоборот снизить ее. Например, большое количество индексов в таблице снижает производительность инструкций INSERT, UPDATE, DELETE и MERGE, потому что при изменении данных в таблице все индексы должны быть изменены соответствующим образом. Общие рекомендации по проектированию индексов мы с Вами рассмотрим в отдельном материале, а сейчас давайте переходить непосредственно к рассмотрению процесса создания и удаления индексов.
Примечание! В качестве SQL сервера у меня выступает версия Microsoft SQL Server 2016 Express.
Создание индексов
Для создания индексов в Microsoft SQL Server существует два способа: первый – это с помощью графического интерфейса среды SQL Server Management Studio (SSMS), и второй – это с помощью языка Transact-SQL, мы с Вами разберем оба способа.
Исходные данные для примеров
Давайте представим, что у нас есть таблица с товарами под названием TestTable, в которой есть три столбца:
Пример создания кластеризованного индекса
Как я уже говорил, кластеризованный индекс создается автоматически, если мы, например, при создании таблицы указываем конкретный столбец в качестве первичного ключа (PRIMARY KEY), но так как мы этого не сделали, давайте рассмотрим пример самостоятельного создания кластеризованного индекса.
Для создания кластеризованного индекса мы можем у таблицы указать первичный ключ, и тем самым кластеризованный индекс будет создан автоматически или мы можем создать кластеризованный индекс отдельно.
Для примера давайте просто создадим кластеризованный индекс, без создания первичного ключа. Сначала сделаем это с помощью Management Studio.
Открываем SSMS и в обозревателе объектов находим нужную таблицу и щелкаем правой кнопкой мыши по пункту «Индексы», выбираем «Создать индекс» и тип индекса, в нашем случае «Кластеризованный».
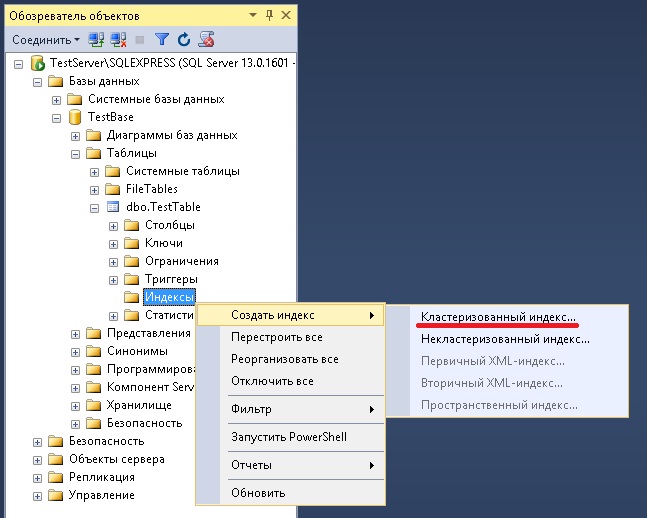
Откроется форма «Новый индекс», где нам необходимо указать имя нового индекса (оно должно быть уникальным в пределах таблицы), также указываем, будет ли этот индекс уникальным, если мы говорим об идентификаторе товара в таблице товаров, то, конечно же, он должен быть уникальным. Потом выбираем столбец (ключ индекса), на основе которого у нас будет создан кластеризованный индекс, т.е. будут отсортированы строки данных в таблице, с помощью кнопки «Добавить».
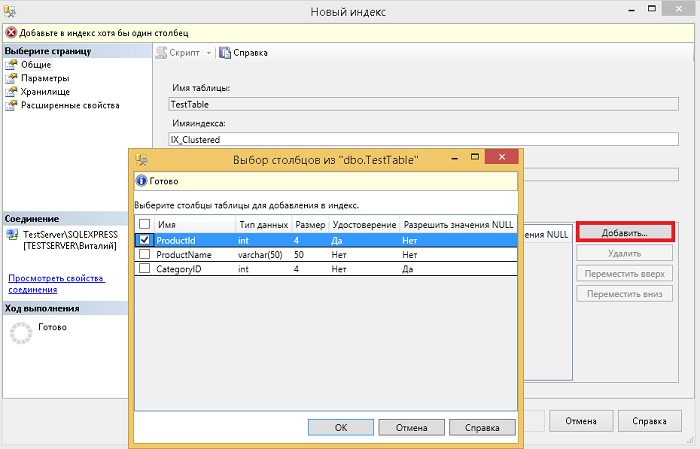
После ввода всех необходимых параметров жмем «ОК», в итоге будет создан кластеризованный индекс.
Точно также можно было бы создать кластеризованный индекс, используя инструкцию T-SQL CREATRE INDEX, например, вот так
Или, как мы уже говорили, можно было бы использовать и инструкцию создания первичного ключа, например
Пример создания некластеризованного индекса с включенными столбцами
Сейчас давайте рассмотрим пример создания некластеризованного индекса, при этом мы укажем столбцы, которые не будет являться ключевыми, но будут включаться в индекс. Это полезно в тех случаях, когда Вы создаете индекс для конкретного запроса, например, для того чтобы индекс полностью покрывал запрос, т.е. содержал все столбцы (это называется «Покрытием запроса»). Благодаря покрытию запроса повышается производительность, так как оптимизатор запросов может найти все значения столбцов в индексе, при этом не обращаясь к данным таблиц, что приводит к меньшему числу дисковых операций ввода-вывода. Но помните, что включение в индекс неключевых столбцов влечет за собой увеличение размера индекса, т.е. для хранения индекса потребуется больше места на диске, а также может повлечь и снижение производительности операций INSERT, UPDATE, DELETE и MERGE на базовой таблице.
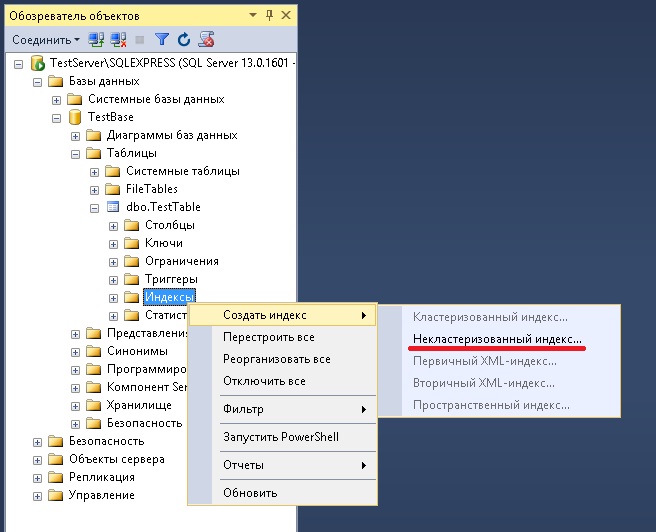
После открытия формы «Новый индекс» мы указываем название индекса, добавляем ключевой столбец или столбцы с помощью кнопки «Добавить», например, для нашего тестового случая давайте укажем CategoryID.
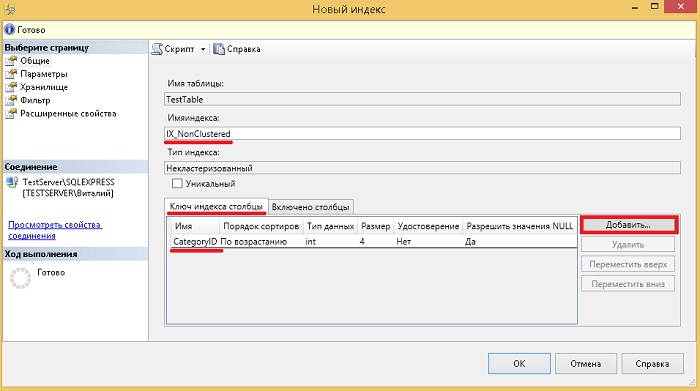
Далее переходим на вкладку «Включено столбцы» и с помощью кнопки «Добавить» добавляем столбцы, которые мы хотим включить в индекс, в нашем случае, например, ProductName.
На Transact-SQL это будет выглядеть следующим образом.
Пример удаления индекса в Microsoft SQL Server
Для того чтобы удалить индекс можно щелкнуть правой кнопкой по нужному индексу и нажать «Удалить», затем подтвердить свое действия нажав «ОК».
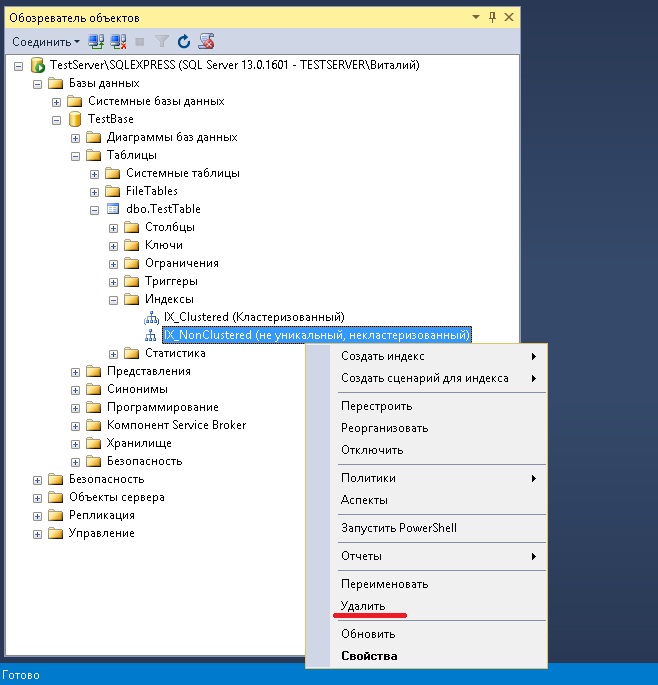
или также можно использовать инструкцию DROP INDEX, например
Следует отметить, что инструкция DROP INDEX неприменима к индексам, которые были созданы путем создания ограничений PRIMARY KEY и UNIQUE. В данном случае для удаления индекса нужно использовать инструкцию ALTER TABLE с предложением DROP CONSTRAINT.
Оптимизация индексов в Microsoft SQL Server
В результате выполнения операций обновления, добавления или удаления данных в таблицах SQL сервер автоматически вносит соответствующие изменения в индексы, но со временем все эти изменения могут вызвать фрагментацию данных в индексе, т.е. они окажутся разбросанными по базе данных. Фрагментация индексов влечет за собой снижение производительности запросов, поэтому периодически необходимо выполнять операции обслуживания индексов, а именно дефрагментацию, к таким можно отнести операции реорганизации и перестроения индексов.
В каких случаях использовать реорганизацию индекса, а в каких перестроение?
Чтобы ответить на этот вопрос сначала необходимо определить степень фрагментации индекса, так как в зависимости от фрагментации индекса тот или иной метод дефрагментации будет предпочтительней и эффективней. Для определения степени фрагментации индекса можно использовать системную табличную функцию sys.dm_db_index_physical_stats, которая возвращает подробные сведения о размере и фрагментации индексов. Например, используя следующий запрос, Вы можете узнать степень фрагментации индексов у всех таблиц в текущей базе данных.
В данном случае нас интересует столбец avg_fragmentation_in_percent, т.е. процентная доля логической фрагментации.
Так вот, Microsoft рекомендует:
Лично я могу добавить следующее, если у Вас небольшая компания и база данных не требует максимальной отдачи в режиме 24 часа в сутки, т.е. она не суперактивная БД, то Вы можете смело периодически выполнять операцию перестроения индексов, при этом даже не определяя степень фрагментации.
Реорганизация индексов
Реорганизация индекса – это процесс дефрагментации индекса, который дефрагментирует конечный уровень кластеризованных и некластеризованных индексов по таблицам и представлениям, физически переупорядочивая страницы концевого уровня в соответствии с логическим порядком (слева направо) конечных узлов.
Для реорганизации индекса можно использовать как графический инструмент SSMS, так и инструкцию Transact-SQL.
Реорганизация индекса с помощью Management Studio
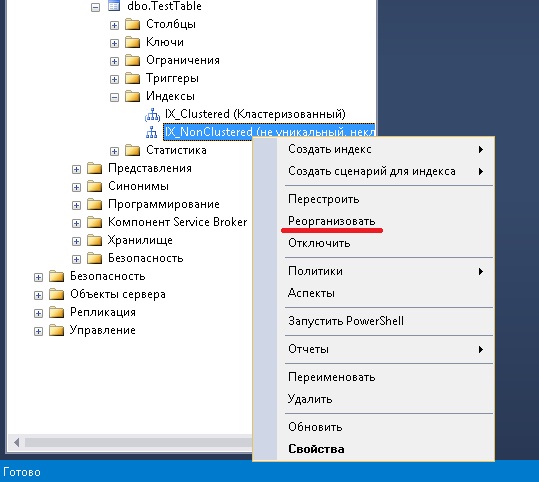
Реорганизация индекса с помощью Transact-SQL
Перестроение индексов
Перестроение индекса – это процесс, при котором происходит удаление старого индекса и создание нового, в результате чего фрагментация устраняется.
Для перестроения индексов можно использовать два способа.
Первый. Используя инструкцию ALTER INDEX с предложением REBUILD. Эта инструкция заменяет инструкцию DBCC DBREINDEX. Обычно для массового перестроения индексов используется именно этот способ.
И второй, используя инструкцию CREATE INDEX с предложением DROP_EXISTING. Можно использовать, например, для перестроения индекса с изменением его определения, т.е. добавления или удаления ключевых столбцов.
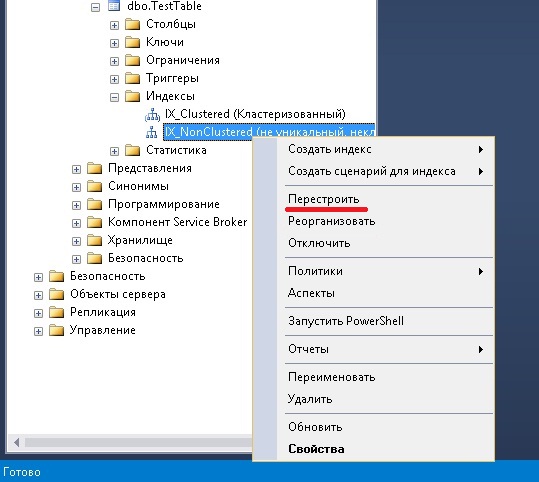
В Management Studio функционал для перестроения также доступен. Правой кнопкой по нужному индексу «Перестроить».
На этом материал по основам индексов в Microsoft SQL Server закончен, если Вас интересует SQL и T-SQL, рекомендую посмотреть мои видеокурсы по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать с использованием языка T-SQL в Microsoft SQL Server, удачи!
Руководство по архитектуре и разработке индексов SQL Server
Плохо спроектированные индексы и их недостаточное количество — основной источник узких мест в приложениях баз данных. Проектирование эффективных индексов имеет первостепенную важность для достижения высокой производительности баз данных и приложений. Это руководство по проектированию индексов SQL Server содержит сведения об архитектуре индексов и рекомендации, руководствуясь которыми, вы сможете создавать эффективные индексы, удовлетворяющие потребностям ваших приложений.
Предполагается, что читатель обладает общими знаниями типов индексов, которые есть в SQL Server. Общее описание типов индексов приведено в разделе Типы индексов.
В этом руководстве рассматриваются следующие типы индексов:
Сведения о пространственных индексах см. в разделе Общие сведения о пространственных индексах.
Сведения о полнотекстовых индексах см. в разделе Заполнение полнотекстовых индексов.
Основы проектирования индексов
Представьте себе обычную книгу: в конце книги есть указатель, который помогает быстро находить информацию в книге. Указатель представляет собой отсортированный список ключевых слов, а рядом с ключевым словом — номера страниц, где можно найти каждое ключевое слово. Индекс SQL Server устроен так же. Это упорядоченный список значений, и для каждого значения есть указатели на страницы данных, где находятся эти значения. Сам индекс хранится на страницах индексов в SQL Server. В обычной книге, если указатель занимает несколько страниц и необходимо найти указатели на все страницы, содержащие слово «SQL», например, вам придется листать до тех пор, пока вы не найдете страницу указателя с ключевым словом «SQL». После этого можно следовать указателям на все страницы книги. Этот процесс можно оптимизировать, если в самом начале индекса создать одну страницу, содержащую алфавитный список расположения каждой буквы. Пример: буквы от А до Г — стр. 121, буквы от Д до Ж — стр. 122 и т. д. Благодаря этой дополнительной странице не придется перелистывать указатель, чтобы найти нужное место. Такая страница не существует в обычных книгах, но существует в индексе SQL Server. Эта единственная страница называется корневой страницей индекса. Корневая страница — это начальная страница древовидной структуры, используемой индексом SQL Server. Следуя аналогии дерева, конечные страницы, содержащие указатели на реальные данные, называются «листьями» дерева.
Индекс SQL Server является структурой на диске или в памяти, которая связана с таблицей или представлением и ускоряет получение строк из таблицы или представления. Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Для индексов на диске эти ключи хранятся в виде структуры сбалансированного дерева, которая поддерживает быстрый поиск строк по значениям ключей в SQL Server.
Выбор правильных индексов для базы данных и ее рабочей нагрузки — это решение сложной задачи о соотношении скорости обработки запроса и стоимости обновления. Узкие индексы, то есть индексы, в ключе которых мало столбцов, требуют меньше места на диске и меньше текущих издержек. С другой стороны, широкие индексы охватывают больше запросов. Прежде чем удастся найти наиболее эффективный индекс, возможно, придется поэкспериментировать с несколькими различными вариантами. Добавление, изменение и удаление индексов не влияет на схему базы данных или конструкцию приложений. Следовательно, эксперименты с различными индексами можно проводить без каких-либо опасений.
Оптимизатор запросов в SQL Server с большой вероятностью выбирает наилучший индекс в подавляющем большинстве случаев. Общая стратегия разработки индексов должна давать оптимизатору запросов по возможности разнообразные варианты, чтобы ему было из чего выбирать. Следует довериться его решению. Это уменьшит время анализа и обеспечит высокую производительность в различных ситуациях. Чтобы выяснить, какие индексы оптимизатор запросов использует для отдельных запросов, в меню Запрос среды SQL Server Management Studio выберите Включить действительный план выполнения.
Использование индекса не всегда означает высокую производительность, а высокая производительность не всегда означает эффективное использование индекса. Если бы использование индекса всегда способствовало производительности, то работа оптимизатора запросов была бы очень простой. На самом деле, неверный выбор индекса может привести к неоптимальной производительности. Следовательно, задача оптимизатора запросов состоит в том, чтобы выбрать индекс или комбинацию индексов, если это улучшит производительность, и избежать индексированного поиска, если это ее понизит.
1 Rowstore — это традиционный способ хранения реляционных данных таблиц. В SQL Server rowstore — это таблица с базовым форматом хранения данных «куча», «сбалансированное дерево» (кластеризованный индекс) или «таблица, оптимизированная для памяти».
Задачи проектирования индексов
Рекомендуемая стратегия проектирования индексов включает в себя следующие задачи:
Прежде всего следует понять характеристики самой базы данных.
Определите наиболее часто используемые запросы. Например, если известно, что часто используется запрос на соединение двух и более таблиц, это поможет определить наилучший тип индексов.
Выясните характеристики столбцов, используемых в запросах. Например, идеальным будет индекс для столбцов с типом данных integer, которые к тому же имеют уникальные или отличные от NULL значения. Для столбцов с хорошо определенными подмножествами данных в SQL Server 2008 и более поздних версиях можно использовать отфильтрованный индекс. Дополнительные сведения см. в разделе Рекомендации по проектированию отфильтрованных индексов этого руководства.
Определите оптимальное расположение для хранения индекса. Некластеризованный индекс может храниться в той же файловой группе, что и базовая таблица, или в другой группе. Правильный выбор расположения для хранения индексов может повысить производительность запросов за счет повышения скорости дискового ввода-вывода. Например, если некластеризованный индекс хранится в файловой группе не на том диске, на котором расположены файловые группы таблицы, то производительность может повыситься, поскольку это позволяет одновременно обращаться к нескольким дискам.
Кластеризованные и некластеризованные индексы могут использовать схему секционирования, которая охватывает несколько файловых групп. Секционирование делает большие таблицы и индексы более управляемыми, позволяет быстро и эффективно получать доступ к наборам данных и управлять ими, при этом сохраняя целостность всей коллекции. Дополнительные сведения см. в разделе Partitioned Tables and Indexes. При выборе секционирования определите, требуется ли выравнивание индекса, то есть должен ли индекс быть секционирован точно так же, как и таблицы, или он может быть секционирован иным образом.
Общие рекомендации по проектированию индексов
Опытный администратор базы данных может спроектировать хороший набор индексов, но эта задача очень сложна, требует много времени и сопряжена с ошибками даже для рабочих нагрузок и баз данных средней сложности. В разработке оптимальных индексов может помочь понимание характеристик базы данных, запросов и столбцов данных.
Соображения, связанные с базами данных
При проектировании индекса следует учитывать следующие рекомендации:
Избегайте использования чрезмерного количества индексов для интенсивно обновляемых таблиц и следите, чтобы индексы были узкими, то есть содержали как можно меньше столбцов.
Используйте большое количество индексов, чтобы улучшить производительность запросов для таблиц с низкими требованиями к обновлениям, но большими объемами данных. Большое число индексов может повысить производительность запросов, которые не изменяют данных, таких как инструкции SELECT, поскольку у оптимизатора запросов будет больший выбор индексов при определении самого быстрого способа доступа.
Индексирование маленьких таблиц может оказаться не лучшим выбором, так как поиск данных в индексе может потребовать у оптимизатора запросов больше времени, чем простой просмотр таблицы. Следовательно, для маленьких таблиц индексы могут вообще не использоваться, но тем не менее их необходимо поддерживать при изменении данных в таблице.
Индексы представлений могут дать значительное улучшение производительности, если представление содержит агрегаты, соединения таблиц или сочетание того и другого. Необязательно явно ссылаться в запросе на представление, чтобы его мог использовать оптимизатор запросов.
Для анализа базы данных и получения рекомендаций по созданию индексов следует использовать помощник по настройке ядра СУБД. Дополнительные сведения см. в разделе Database Engine Tuning Advisor.
Вопросы работы с запросами
При проектировании индекса следует принимать во внимание следующие рекомендации, связанные с обработкой запросов.
Покрывающими индексами называются некластеризованные индексы, которые разрешают один или несколько схожих результатов запроса напрямую, без доступа к базовой таблице и без уточняющих запросов. Такие индексы имеют на конечном уровне все необходимые столбцы, отличные от SARGable. Это означает, что индекс включает столбцы, возвращаемые предложением SELECT и указываемые в любых аргументах WHERE и JOIN. Это позволяет существенно снизить объем операций ввода-вывода для выполнения запроса, если индекс будет достаточно узким по сравнению с количеством строк и столбцов в самой таблице, то есть будет правильным подмножеством ее столбцов. Используйте покрывающие индексы, при обращении к небольшому фрагменту большой таблицы, который определяется фиксированным предикатом, например разреженными столбцами с малым числом непустых значений.
Запросы следует составлять так, чтобы они вставляли или изменяли как можно больше строк одной инструкцией, вместо того, чтобы использовать для обновления тех же строк нескольких запросов. Используя только одну инструкцию, можно воспользоваться возможностями, которые обеспечивает поддержание оптимизированного индекса.
Определите тип запроса и то, как в нем используются столбцы. Например: столбец, который используется в запросе с точным соответствием, может оказаться подходящим кандидатом для создания кластеризованного или некластеризованного индекса.
Вопросы работы со столбцами
При проектировании индекса, следует принимать во внимание следующие рекомендации, относящиеся к столбцам.
Нужно следить, чтобы длина ключа для кластеризованных индексов была небольшой. Кроме того, кластеризованные индексы только выиграют при создании на основе уникальных или не принимающих значения NULL столбцах.
Столбцы типа xml могут быть ключевым столбцом только в XML-индексе. Дополнительные сведения см в разделе XML-индексы (SQL Server). С пакетом обновления 1 (SP1) в SQL Server 2012 появился новый тип XML-индекса — выборочный XML-индекс. Этот новый индекс повышает производительность запросов для данных, хранимых в виде XML на SQL Server, и тем самым значительно ускоряет индексирование рабочих нагрузок XML-данных большого объема и повышает масштабируемость за счет уменьшения места хранения самого индекса. Дополнительные сведения см. в разделе Выборочный XML-индекс (SXI).
Проверьте уникальность столбцов. Замена неуникального индекса уникальным для той же комбинации столбцов обеспечивает оптимизатору запросов дополнительные сведения, что делает индекс более полезным. Дополнительные сведения см. в разделе Правила по созданию уникальных индексов этого руководства.
Проверьте распределение данных в столбце. Часто длительное выполнение запроса обусловлено индексированием столбца, в котором мало уникальных значений, или присоединением такого столбца. Это фундаментальная проблема, связанная с данными и запросом, и обычно она не может быть решена без определения ситуации. Например: физический телефонный справочник, отсортированный в алфавитном порядке по фамилии, не сможет быстро найти человека, если всех жителей города зовут Смит или Джонс. Дополнительные сведения о распределении данных см. в разделе Statistics.
Попробуйте применить отфильтрованные индексы для столбцов, имеющих точно определенные подмножества, например разреженных столбцов, столбцов, содержащих в основном значения NULL, столбцов с разнородными категориями значений и столбцов с различными диапазонами значений. Правильно составленный отфильтрованный индекс может увеличить скорость выполнения запроса, уменьшить стоимость обслуживания индекса и стоимость хранения.
Следует рассмотреть возможность индексирования вычисляемых столбцов. Дополнительные сведения см. в разделе Индексы вычисляемых столбцов.
Характеристики индекса
После того, как определено, что индекс соответствует запросу, можно выбрать наилучший тип индекса для конкретной ситуации. Ниже представлены характеристики индекса:
Также можно задать начальные характеристики хранилища индекса, чтобы оптимизировать его производительность или поддержание, задав такие параметры, как FILLFACTOR. Чтобы оптимизировать производительность, можно также определить место хранения индекса с помощью файловых групп или схем секционирования.
Размещение индекса в файловых группах или схемах секций
Во время разработки стратегии индексирования следует обратить внимание на помещение индексов в файловые группы, связанные с базой данных. Аккуратный выбор схемы файловой группы или секционирования может улучшить производительность.
По умолчанию индексы хранятся в той же файловой группе, что и базовая таблица, для которой создается индекс. Несекционированный некластеризованный индекс и базовая таблица всегда находятся в одной файловой группе. Однако можно сделать следующее.
Поскольку тип и время необходимого доступа спрогнозировать невозможно, лучшим решением может оказаться распределение таблиц и индексов по всем файловым группам. Это гарантирует, что доступ будет осуществляться ко всем дискам, так как все данные и индексы равномерно распределены по ним, независимо от способа доступа к данным. Для системных администраторов этот подход также более прост.
Секции во многих файловых группах
Можно рассмотреть возможность секционирования кластеризованных и некластеризованных индексов по нескольким файловым группам. Секционированные индексы разбиваются горизонтально или построчно, в зависимости от функции секционирования. Функция секционирования определяет, как каждая строка сопоставляется с набором секций на основе значений определенных столбцов — столбцов секционирования. Схема секционирования определяет сопоставление секций набору файловых групп.
Секционирование индекса может предоставить следующие преимущества.
Система становится более масштабируемой, а управление большими индексами в ней упрощается. Например, в системах OLTP можно реализовать приложения, учитывающие секционирование и работающие с большими индексами.
Запросы выполняются быстрее и эффективнее. Когда запросы выполняются в нескольких секциях индекса, оптимизатор запросов может обрабатывать определенные секции в одно и то же время и исключать секции, к которым запрос не относится.
Дополнительные сведения см. в разделе Partitioned Tables and Indexes.
Рекомендации по созданию порядка сортировки индексов
При определении индексов следует иметь в виду, что данные ключевых столбцов индекса сохраняются в порядке возрастания или убывания. По умолчанию сортировка производится по возрастанию, как и в предыдущих версиях SQL Server. Синтаксис инструкций CREATE INDEX, CREATE TABLE и ALTER TABLE поддерживает ключевые слова ASC (по возрастанию) и DESC (по убыванию) для конкретных столбцов в индексах и ограничениях.
Указание порядка, в котором значения ключей хранятся в индексе, полезно тогда, когда запрос ссылается на таблицу с предложением ORDER BY, в котором указано другое направление для ключевого столбца индекса или индексированного столбца. В этом случае индекс может исключить необходимость в операторе SORT в плане запроса, то есть запрос будет выполняться значительно эффективнее. Например, покупателю в отделе заказов Компания Adventure Works Cycles необходимо определить качество товаров от разных поставщиков. Больше всего его интересуют товары тех поставщиков, которые имеют набольшую частоту отказов. Как показано в следующем запросе, получение данных по соответствию этому критерию требует, чтобы столбец RejectedQty в таблице Purchasing.PurchaseOrderDetail был отсортирован в порядке убывания (от большего значения к меньшему), а столбец ProductID — в порядке возрастания (от меньшего к большему).
Следующий план выполнения для этого запроса показывает, что оптимизатор запросов применяет оператор SORT для результирующего набора в порядке, указываемом предложением ORDER BY.

Если создан индекс для ключевых столбцов, который соответствует индексу, указанному в предложении ORDER BY, оператор SORT может быть исключен из плана запроса, что значительно повысит его эффективность.
После повторного выполнения запроса план выполнения показывает, что оператор SORT исключен и используется вновь созданный некластеризованный индекс.

Порядок сортировки может быть указан только для ключевых столбцов в индексе. Представление каталога sys.index_columns и функция INDEXKEY_PROPERTY помогут определить, в каком порядке хранится столбец индекса — возрастающем или убывающем.
Метаданные
Используйте приведенные ниже представления метаданных, чтобы увидеть атрибуты индексов. В некоторых из этих представлений содержатся дополнительные сведения об архитектуре.
Все столбцы в индексах columnstore хранятся в метаданных как включенные столбцы. Индекс columnstore не имеет ключевых столбцов.