particle swarm optimization
оптимизация по сгустку частиц
(напр. загрязнителей атмосферы)
[А.С.Гольдберг. Англо-русский энергетический словарь. 2006 г.]
Тематики
Смотреть что такое «particle swarm optimization» в других словарях:
Particle swarm optimization — (PSO) is a swarm intelligence based algorithm to find a solution to an optimization problem in a search space, or model and predict social behavior in the presence of objectives.OverviewParticle swarm optimization is a stochastic, population… … Wikipedia
Repulsive particle swarm optimization — In mathematics, specifically in optimization, repulsive particle swarm optimization (RPSO) is a global optimization algorithm. It belongs to the class of stochastic evolutionary global optimizers, and is a variant of particle swarm optimization… … Wikipedia
Swarm intelligence — (SI) is artificial intelligence based on the collective behavior of decentralized, self organized systems. The expression was introduced by Gerardo Beni and Jing Wang in 1989, in the context of cellular robotic systems [ Beni, G., Wang, J. Swarm… … Wikipedia
Optimization (mathematics) — In mathematics, the term optimization, or mathematical programming, refers to the study of problems in which one seeks to minimize or maximize a real function by systematically choosing the values of real or integer variables from within an… … Wikipedia
Ant colony optimization algorithms — Ant behavior was the inspiration for the metaheuristic optimization technique. In computer science and operations research, the ant colony optimization algorithm (ACO) is a probabilistic technique for solving computational problems which can be… … Wikipedia
Meta-optimization — concept. In numerical optimization, meta optimization is the use of one optimization method to tune another optimization method. Meta optimization is reported to have been used as early as in the late 1970s by Mercer and Sampson [1] for finding… … Wikipedia
Ant colony optimization — The ant colony optimization algorithm (ACO), introduced by Marco Dorigo in 1992 in his PhD thesis, is a probabilistic technique for solving computational problems which can be reduced to finding good paths through graphs. They are inspired by the … Wikipedia
Category:Optimization algorithms — An optimization algorithm is an algorithm for finding a value x such that f(x) is as small (or as large) as possible, for a given function f, possibly with some constraints on x. Here, x can be a scalar or vector of continuous or discrete values … Wikipedia
Global optimization — is a branch of applied mathematics and numerical analysis that deals with the optimization of a function or a set of functions to some criteria. General The most common form is the minimization of one real valued function f in the parameter space … Wikipedia
Mathematical optimization — For other uses, see Optimization (disambiguation). The maximum of a paraboloid (red dot) In mathematics, computational science, or management science, mathematical optimization (alternatively, optimization or mathematical programming) refers to… … Wikipedia
Multidisciplinary design optimization — Multi disciplinary design optimization (MDO) is a field of engineering that uses optimization methods to solve design problems incorporating a number of disciplines. As defined by Prof. Carlo Poloni, MDO is the art of finding the best compromise … Wikipedia
Алгоритм роя частиц
Введение
Стая птиц представляет собой прекрасный пример коллективного поведения животных. Летая большими группами, они почти никогда не сталкиваются в воздухе. Стая двигается плавно и скоординировано, словно ей кто-то управляет. А любой, кто вешал в своем дворе кормушку, знает, что спустя несколько часов его найдут все птицы в округе.

Дело тут отнюдь не в вожаке, отдающем приказы – в стаях многих видов птиц его просто нет. Как и колония муравьев или пчел, стая представляет собой роевой интеллект. Птицы в ней действуют согласно определенным – довольно простым – правилам. Кружа в небе, каждая из птиц следит за своими сородичами и координирует свое движение согласно их положению. А найдя источник пищи, она оповестит их об этом.
На последнем факте следует остановиться подробнее, поскольку он играет одну из ключевых ролей в рассматриваемом методе оптимизации. Причины такого «альтруизма» птиц (и других животных, действующих сходным образом) являлись предметом исследования многих социобиологов. Одним из наиболее популярных объяснений этого феномена является то, что преимущества от такого поведения каждой особи стаи больше, чем такие очевидные недостатки, как необходимость борьбы за найденную пищу с другими особями.
Источники пищи обычно расположены случайным образом, поэтому в одиночестве птица вполне может погибнуть, не найдя ни один в течение долгого времени. Однако если все птицы будут «играть по правилам», делясь с сородичами информацией о находках, то шансы каждой из них на выживание резко повышаются. Таким образом, будучи неэффективной для отдельной особи, такая стратегия является залогом эффективности стаи и вида в целом.
Boids
Наблюдение за птицами вдохновило Крейга Рейнольдса (Craig Reynolds) на создание в 1986 году компьютерной модели, которую он назвал Boids. Для имитации поведения стаи птиц, Рейнольдс запрограммировал поведение каждой из них в отдельности, а также их взаимодействие. При этом он использовал три простых принципа. Во-первых, каждая птица в его модели стремилась избежать столкновений с другими птицами. Во-вторых, каждая птица двигалась в том же направлении, что и находящиеся неподалеку птицы. В-третьих, птицы стремились двигаться на одинаковом расстоянии друг от друга.
Результаты первых же симуляций удивили самого создателя: несмотря на простоту лежащих в основе программы алгоритмов, стая на экране выглядела крайне правдоподобно. Птицы сбивались в группы, уходили от столкновений и даже хаотично метались точь-в-точь как настоящие.
Как специалист в области компьютерной графики, Крейг Рейнольдс был в первую очередь заинтересован визуальной стороной результатов созданной им имитации. Однако, в посвященной Boids статье он также отметил, что разработанная им поведенческая модель может быть расширена введением дополнительных факторов – таких, как поиск пищи или боязнь хищников [1].
Классический алгоритм роя частиц
В 1995 году Джеймс Кеннеди (James Kennedy) и Рассел Эберхарт (Russel Eberhart) предложили метод для оптимизации непрерывных нелинейных функций, названный ими алгоритмом роя частиц [2]. Вдохновением для них послужила имитационная модель Рейнольдса, а также работа Хеппнера (Heppner) и Гренадера (Grenader) на схожую тему [4]. Кеннеди и Эберхарт отметили, что обе модели основаны на управлении дистанциями между птицами – а, следовательно, синхронность стаи является в них функцией от усилий, которые птицы прилагают для сохранения оптимальной дистанции.
Разработанный ими алгоритм довольно прост и может быть реализован буквально в нескольких десятках строчек кода на любом высокоуровневом языке программирования. Он моделирует многоагентную систему, где агенты-частицы двигаются к оптимальным решениям, обмениваясь при этом информацией с соседями.
Текущее состояние частицы характеризуется координатами в пространстве решений (то есть, собственно, связанным с ними решением), а также вектором скорости перемещения. Оба этих параметра выбираются случайным образом на этапе инициализации. Кроме того, каждая частица хранит координаты лучшего из найденных ей решений, а также лучшее из пройденных всеми частицами решений – этим имитируется мгновенный обмен информацией между птицами.
На каждой итерации алгоритма направление и длина вектора скорости каждой из частиц изменяются в соответствие со сведениями о найденных оптимумах:
 ,
,
где – вектор скорости частицы (  – его i-ая компонента), , – постоянные ускорения, – лучшая найденная частицей точка, – лучшая точка из пройденных всеми частицами системы, – текущее положение частицы, а функция возвращает случайное число от 0 до 1 включительно.
– его i-ая компонента), , – постоянные ускорения, – лучшая найденная частицей точка, – лучшая точка из пройденных всеми частицами системы, – текущее положение частицы, а функция возвращает случайное число от 0 до 1 включительно.
После вычисления направления вектора , частица перемещается в точку 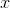 . В случае необходимости, обновляются значения лучших точек для каждой частицы и для всех частиц в целом. После этого цикл повторяется.
. В случае необходимости, обновляются значения лучших точек для каждой частицы и для всех частиц в целом. После этого цикл повторяется.
Модификации классического алгоритма
Алгоритм роя частиц появился относительно недавно, однако различными исследователями уже был предложен целый ряд его модификаций, и новые работы на эту тему не перестают публиковаться. Можно выделить несколько путей улучшения классического алгоритма, реализованных в большинстве из них. Это соединение алгоритма с другими алгоритмами оптимизации, уменьшение вероятности преждевременной сходимости путем изменения характеристик движения частиц, а также динамическое изменение параметров алгоритма во время оптимизации. Ниже рассмотрены наиболее примечательные из модификаций.
LBEST
Позже в том же 1995 году была опубликована статья Кеннеди и Эберхарта, в которой они назвали оригинальный алгоритм “GBEST”, поскольку он использует глобальное лучшее решение (global best) для формирования векторов скоростей, а также предложили его модификацию, названную ими “LBEST”. При обновлении направления и скорости движения частицы в LBEST используют информацию о решениях соседних с ними частиц:
,
где – лучший результат среди частицы и ее соседей. Соседними считаются либо частицы, отличающихся от данной индексом не более чем на некоторое заданное значение, либо частицы, расстояние до которых не превышает заданного порога.
Данный алгоритм более тщательно исследует пространство поиска, однако является более медленным, чем оригинальный. При этом, чем меньшее число соседей учитывается при формировании вектора скорости, тем ниже скорость сходимости алгоритма но тем эффективней он избегает субоптимальных решений.
Inertia Weighted PSO
В 1998 году Юхи Ши (Yuhui Shi) и Рассел Эберхарт предложили модификацию, на первый взгляд совсем незначительно отличающуюся от классического алгоритма [5]. В своей статье Ши и Эберхарт заметили, что одной из главных проблем при решении задач оптимизации является баланс между тщательностью исследованием пространства поиска и скоростью сходимости алгоритма. В зависимости от задачи и характеристик поискового пространства в ней, этот баланс должен быть различным.
С учетом этого, Ши и Эберхарт предложили изменить правило обновления векторов скоростей частиц:
,
Коэффициент , названный ими коэффициентом инерции, определяет упомянутый баланс между широтой исследования и вниманием к найденным субоптимальным решениям. В случае, когда 1″/>, скорости частиц увеличиваются, они разлетаются в стороны и исследуют пространство более тщательно. В противном случае, скорости частиц со временем уменьшаются, и скорость сходимости в таком случае зависит от выбора параметров и .
Time-Varying Inertia Weighted PSO
В своей работе 1998 года, Ши и Эберхарт отметили, что инерция не обязательно должна быть положительной константой: она может изменяться во время работы алгоритма по линейному и даже нелинейному закону [5]. В статье 1999 года и более поздних работах они наиболее часто использовали линейный закон убывания, как достаточно эффективный и вместе с тем простой [6]. Тем не менее, разрабатывались и успешно применялись и другие законы изменения инерции.
Значение коэффициента инерции может как убывать, так и расти. При его убывании, частицы сначала исследуют область поиска экстенсивно, находя множество субоптимальных решений, и со временем все более концентрируются на исследовании их окрестностей. Возрастание инерции способствует сходимости алгоритма на поздних стадиях работы.
Canonical PSO
В 2002 году Марис Клер (Maurice Clerc) и Джеймс Кеннеди предложили свою модификацию алгоритма роя частиц, которая стала настолько популярной, что теперь ее принято называть каноническим алгоритмом роя частиц [7]. Он позволяет избавиться от необходимости «угадывать» подходящие значения регулируемых параметров алгоритма, контролируя сходимость частиц.
Клер и Кеннеди изменили способ вычисления векторов скоростей частиц, введя в него дополнительный множитель:
,
где , а коэффициент сжатия равен:
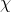 .
.
Такой подход гарантирует сходимость алгоритма без необходимости явно контролировать скорость частиц.
Fully Informed Particle Swarm
В своей работе 2004 года Руи Мендес (Rui Mendes), Джеймс Кеннеди и Жозе Невес (José Neves) заметили, что принятое в каноническом алгоритм роя частиц допущение о том, что на каждую из частиц влияет только наиболее успешная, не соответствует лежащим в его основе природным механизмам и, возможно, ведет к снижению эффективности алгоритма [8]. Они предположили, что из-за чрезмерного внимания алгоритма к единственному решению может быть потеряна важная информация о структуре пространства поиска.
Исходя из этого, они решили сделать все частицы «полностью информированными», то есть получающими информацию от всех соседних частиц. Для этого они изменили в каноническом алгоритме закон изменения скорости:
,
где – множество соседей частицы, 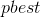 – лучшая из пройденных k-ым соседом точек. – весовая функция, которая может отражать любую характеристику k-ой частицы, которая считается важной: значение целевой функции в точке, в которой она находится, дистанцию от нее до данной частицы и так далее.
– лучшая из пройденных k-ым соседом точек. – весовая функция, которая может отражать любую характеристику k-ой частицы, которая считается важной: значение целевой функции в точке, в которой она находится, дистанцию от нее до данной частицы и так далее.
Заключение
В первой статье, описывающей алгоритм роя частиц, Джеймс Кеннеди и Рассел Эберхарт высказывали идею использования алгоритм для имитации социального поведения – Кеннеди, как социального психолога, крайне привлекала эта идея [1]. Однако наибольшее распространение алгоритм получил в задачах оптимизации сложных многомерных нелинейных функций.
Алгоритм роя частиц широко применяется, в числе прочих, в задачах машинного обучения (в частности, для обучения нейросетей и распознавания изображений), параметрической и структурной оптимизации (форм, размеров и топологий) в области проектирования, в областях биохимии и биомеханики. По эффективности он может соперничать с другими методами глобальной оптимизации, а низкая алгоритмическая сложность способствует простоте его реализации.
Наиболее перспективными направлениями дальнейших исследований в данном направлении следует считать теоретические исследования причин сходимости алгоритма роя частиц и связанных с этим вопросов из областей роевого интеллекта и теории хаоса, комбинирование различных модификаций алгоритма для решения сложных задач, рассмотрение алгоритма роя частиц как многоагентной вычислительной системы, а также исследование возможностей включения в него аналогов более сложных природных механизмов.

СОДЕРЖАНИЕ
Алгоритм
Базовый вариант алгоритма PSO работает, имея популяцию (называемую роем) возможных решений (называемых частицами). Эти частицы перемещаются в пространстве поиска в соответствии с несколькими простыми формулами. Движение частиц определяется их самой известной позицией в пространстве поиска, а также самой известной позицией всего роя. Когда будут обнаружены улучшенные позиции, они будут направлять движения роя. Процесс повторяется, и тем самым можно надеяться, но не гарантировать, что в конечном итоге будет найдено удовлетворительное решение.
Выбор параметра

Выбор параметров PSO может иметь большое влияние на производительность оптимизации. Поэтому выбор параметров PSO, обеспечивающих хорошую производительность, стал предметом многочисленных исследований.
Параметры также были настроены для различных сценариев оптимизации.
Окрестности и топологии
Внутренние работы
Существует несколько мнений относительно того, почему и как алгоритм PSO может выполнять оптимизацию.
Конвергенция
В отношении PSO слово конвергенция обычно имеет два разных определения:
Сходимость к локальному оптимуму была проанализирована для PSO в и. Было доказано, что PSO нуждается в некоторой модификации, чтобы гарантировать нахождение локального оптимума.
Адаптивные механизмы
Без необходимости идти на компромисс между конвергенцией («эксплуатация») и дивергенцией («исследование») может быть введен адаптивный механизм. Адаптивная оптимизация роя частиц (APSO) обеспечивает лучшую эффективность поиска, чем стандартный PSO. APSO может выполнять глобальный поиск по всему пространству поиска с более высокой скоростью сходимости. Это позволяет автоматически контролировать вес инерции, коэффициенты ускорения и другие алгоритмические параметры во время выполнения, тем самым повышая эффективность поиска и в то же время эффективность. Кроме того, APSO может воздействовать на лучшую в мире частицу, чтобы выпрыгнуть из вероятных локальных оптимумов. Тем не менее, APSO представит новые параметры алгоритма, тем не менее, это не приведет к дополнительной сложности проектирования или реализации.
Варианты
Возможны многочисленные варианты даже базового алгоритма PSO. Например, есть разные способы инициализации частиц и скоростей (например, начать с нулевых скоростей вместо этого), как уменьшить скорость, обновлять только p i и g после обновления всего роя и т. Д. Некоторые из этих вариантов и их возможное влияние на производительность обсуждалось в литературе.
Гибридизация
Новые и более сложные варианты PSO также постоянно вводятся в попытке улучшить производительность оптимизации. В этом исследовании есть определенные тенденции; один состоит в том, чтобы создать гибридный метод оптимизации с использованием PSO в сочетании с другими оптимизаторами, например, объединить PSO с оптимизацией на основе биогеографии и включить эффективный метод обучения.
Алгоритмы PSO на основе градиента
Способность алгоритма PSO эффективно исследовать множественный локальный минимум может быть объединена со способностью алгоритмов локального поиска на основе градиента эффективно вычислять точный локальный минимум для создания алгоритмов PSO на основе градиента. В алгоритмах PSO на основе градиента алгоритм PSO используется для исследования многих локальных минимумов и определения точки в бассейне притяжения глубокого локального минимума. Затем используются эффективные алгоритмы локального поиска на основе градиента для точного определения глубокого локального минимума. Вычисление градиентов и гессианов сложных многомерных функций затрат часто требует больших вычислительных затрат и во многих случаях невозможно вручную, что препятствует широкому распространению алгоритмов PSO на основе градиентов. Однако в последние годы наличие высококачественного программного обеспечения для символьной автоматической дифференциации (AD) привело к возрождению интереса к алгоритмам PSO на основе градиентов.
Избавьтесь от преждевременной конвергенции
Упрощения
Еще один аргумент в пользу упрощения PSO заключается в том, что эффективность метаэвристики может быть продемонстрирована только эмпирически, путем проведения вычислительных экспериментов над конечным числом задач оптимизации. Это означает, что нельзя доказать правильность метаэвристики, такой как PSO, и это увеличивает риск совершения ошибок в ее описании и реализации. Хорошим примером этого является многообещающий вариант генетического алгоритма (еще одна популярная метаэвристика), но позже он оказался дефектным, поскольку при поиске оптимизации он был сильно смещен в сторону схожих значений для разных измерений в пространстве поиска, что оказалось оптимальная из рассмотренных тестовых задач. Эта систематическая ошибка возникла из-за ошибки программирования и теперь исправлена.
Инициализация скоростей может потребовать дополнительных входных данных. Вариант Bare Bones PSO был предложен в 2003 году Джеймсом Кеннеди и вообще не требует использования скорости.
Многоцелевая оптимизация
Двоичные, дискретные и комбинаторные
Однако можно отметить, что в уравнениях движения используются операторы, выполняющие четыре действия:
Параллельная оптимизация методом роя частиц (Particle Swarm Optimization)

В данной статье мы реализуем алгоритм роя частиц (Particle Swarm Optimization, PSO) и попытаемся встроить его в тестер MetaTrader для параллельного запуска на доступных локальных агентах. Целевой функцией оптимизации будет выбранный пользователем показатель торговли эксперта.
Метод роя частиц
С алгоритмической точки зрения метод PSO относительно прост. Основная идея состоит в том, чтобы сгенерировать множество виртуальных «частиц» в пространстве входных параметров советника. Затем частицы двигаются и меняют свою скорость в зависимости от показателей торговли советника в соответствующих точках пространства. Процесс повторяется много раз, пока показатели не перестают улучшаться. Псевдо-код алгоритма приведен ниже:

Particle Swarm Optimization Pseudo-Code
Согласно нему каждая частица обладает текущей позицией, скоростью и памятью о своей «лучшей» точке в прошлом. Под «лучшей» имеется в виду точка (набор входных параметров эксперта), где достигалось наибольшее значение целевой функции для этой частицы. Опишем это в классе.
Массивы и переменные сделаны публичными для упрощения доступа и кода их пересчета. Строгое следование принципам ООП потребовало бы скрыть их с помощью модификатора private и описать методы для чтения и модификации.
Помимо отдельных частиц алгоритм оперирует так называемыми «топологиями» или подмножествами частиц. Они могут строиться по разным принципам. Выберем в нашем случае «топологию социальной группы». Такая группа хранит информацию о лучшей позиции среди всех своих частиц.
Принадлежность частицы к группе задается номером группы в поле group в классе Particle (см. выше).
Теперь приступим к кодированию самого алгоритма роя частиц, в виде отдельного класса. Начнем с массивов частиц и групп.
Для каждого параметра необходимо задать диапазон значений, в котором будет выполняться оптимизация, и приращение (шаг).
Кроме того, следует где-то хранить оптимальный набор параметров.
Поскольку класс будет иметь несколько разных конструкторов, опишем унифицированный метод инициализации.
Все массивы распределяются под заданную размерность и заполняются переданными данными. Начальное положение частиц, их скорость и членство в группах определяется случайно. Кое-что важное пока закоментировано, но чуть позже мы раскроем, зачем оно нужно.
Следует отметить, что классический вариант «роя частиц» предназначен для оптимизации функций, определенных на непрерывных координатах. Однако параметры экспертов обычно тестируются с некоторым шагом. В частности, стандартное скользящее среднее не может иметь, например, период 11.5. В связи с этим, помимо диапазона допустимых значений для всех размерностей задается и шаг, который используется для округления позиций частиц. Мы увидим, что это будет делаться не только на фазе инициализации, но и в расчетах в ходе оптимизации.
Теперь мы можем реализовать пару конструкторов с помощью init.
Первый из них использует известное эмпирическое правило по вычислению размера роя и количества групп, основываясь на числе параметров. Константа AUTO_SIZE_FACTOR, равная по умолчанию 5, может меняться по желанию. Второй — позволяет задать все величины явным образом.
Деструктор освобождает распределенную память.
И вот настал момент для написания главного метода класса, выполняющего непосредственно оптимизацию.
Первый параметр Functor &f представляет особый интерес. Очевидно, что в процессе оптимизации мы будем вызывать эксперт для различных входных параметров и в ответ получать оценочное число (прибыль, прибыльность или другую характеристику). Рой ничего не знает и не должен знать об эксперте. Его единственная задача — найти оптимум неизвестной целевой функции с произвольным набором числовых аргументов. Поэтому в ход вступает абстрактный интерфейс, в нашем случае класс Functor.
Единственный метод принимает на входе массив параметров и возвращает число (все типы — double). В дальнейшем эксперт должен будет тем или иным образом реализовать класс, производный от Functor, и вычислять требуемый показатель внутри метода calculate. Таким образом, первый параметр метода optimize получит объект с функцией обратного вызова, предоставляемой торговым роботом.
Второй параметр метода optimize — это максимальное количество циклов для выполнения алгоритма. Следующие 3 параметра задают коэффициенты PSO: inertia — сохранение скорости частицы (благодаря значениям меньше 1, скорость обычно уменьшается), selfBoost и groupBoost определяют, насколько отзывчива частица на подстраивание направления своего движения к лучшим известным позициям, соответственно, в истории самой частицы и её группы.
Теперь, когда все параметры рассмотрены, мы можем приступить к самому алгоритму. В несколько упрощенном виде циклы оптимизации почти полностью воспроизводят псевдо-код.
Метод возвращает найденное максимальное значение целевой функции. Для чтения координат (набора параметров) зарезервирован другой метод.
Вот, практически, и весь алгоритм. Но ранее было не случайно сказано, что в коде есть некоторые упрощения. Прежде всего рассмотрим следующий нюанс.
Дискретный мир без двойников
Функтор многократно вызывается для динамически пересчитывающихся наборов параметров, однако нет никакой гарантии, что алгоритм не попадет несколько раз в одну и ту же точку, особенно учитывая дискретность по осям. Чтобы предотвратить это, необходимо каким-то образом отличать уже рассчитанные точки и пропускать их.
Параметры — это просто числа, последовательность байтов. Наиболее известным приемом для проверки уникальности данных является хэш. А наиболее популярным способом получения хэша можно считать CRC. CRC — это отдельное число (как правило, целое, многоразрядное), генерируемое на основе данных таким образом, что совпадение двух таких характеристических чисел от двух наборов данных с высокой вероятностью означает, что наборы идентичны. Чем больше разрядов (битов) в CRC, тем выше вероятность совпадения (вплоть до практически 100%). 64-битного CRC, пожалуй, достаточно для нашей задачи, но при необходимости его можно расширить и поменять на другую хэш-функцию. Реализацию расчета CRC легко портировать на MQL с языка C. Один из вариантов приложен к данной статье в файле crc64.mqh. Основная рабочая функция имеет следующий прототип.
Она принимает CRC предыдущего блока данных (если их несколько, а для одного блока следует указать 0), массив байтов и сколько элементов из него обработать. Функция возвращает 64-битный CRC.
Нам необходимо подать на вход этой функции набор параметров, но напрямую это сделать нельзя, так как каждый параметр — это число типа double. Для преобразования его в массив байтов будем использовать библиотеку TypeToBytes.mqh (файл приложен к статье, но наиболее актуальную версию лучше брать в codebase).
После включения данной библиотеки мы можем создать функцию «обертку» для расчета CRC64 от массива параметров:
Но возникают следующие вопросы: где хранить хэши и как проверять их на уникальность. Здесь лучше всего подойдет бинарное дерево. Это структура данных, которая обеспечивает быстрые операции добавления новых величин и проверку на существование уже добавленных. Скорость обеспечивается за счет особого свойства дерева, называемого сбалансированностью. Иными словами, дерево должно быть сбалансированным (постоянно поддерживаться в сбалансированном состоянии), чтобы обеспечить максимальную скорость операций над ним. К счастью, тот факт, что в дереве будут храниться хэши, играет нам на руку. Вспомним определение хэша.
Хэш-функция (алгоритм генерации хэшей) генерирует для любых входных данных равномерно распределенную, насколько это возможно, выходную величину. В результате, добавление хэша в бинарное дерево статистически обеспечивает его состояние, близкое к сбалансированному, и, как следствие, высокую эффективность.
Бинарное дерево представляет собой набор узлов, каждый из которых содержит некоторое значение и две опциональных ссылки на, так называемые, правый и левый узел. Значение в левом узле всегда меньше значения в родительском узле, а значение в правом — больше, чем в родительском. Дерево начинает заполняться с корня, путем сравнения нового значения со значениями узлов. Если добавляемое значение равно значению корня (или другого узла), достаточно вернуть признак существования значения в дереве. Если новое значение меньше значения в узле, мы перемещаемся по ссылке на левый узел и обрабатываем сходным образом его поддерево. Если новое значение больше, идем по правому поддереву. Если какая-либо из ссылок нулевая (дальше ветвей нет), поиск завершен безрезультатно и потому следует вместо нулевой ссылки создать новый узел с новым значением.
Для реализации данной логики была создана пара классов-шаблонов: узел TreeNode и дерево BinaryTree. С их полными исходными кодами можно ознакомиться в прилагаемом заголовочном файле.
Метод add возвращает true, если значение уже есть в дереве, и false — если его ранее не было, но оно только что добавлено. Удаление корня в деструкторе дерева автоматически разворачивается в удаление всех дочерних узлов.
Реализованный класс дерева — один из простейших вариантов, существуют более продвинутые деревья, так что желающие могут их встроить самостоятельного.
Добавим BinaryTree в класс Swarm.
В методе optimize следует доработать места, где мы перемещаем частицы на новые позиции.
Мы добавили вспомогательный массив next, куда сперва попадают новые сгенерированные координаты. Для них вычисляется CRC и это значение проверяется на уникальность. Если новая позиция еще не встречалась, она добавляется в дерево, копируется в соответствующую частицу, и для неё выполняются все необходимые вычисления. Если же позиция уже имеется в дереве (т.е. для неё функтор уже вычислялся), данная итерация пропускается.
Тестирование базового функционала
Всё, рассмотренное вышe, составляет минимально необходимую основу для проведения первых тестов. Убедиться, что оптимизация действительно работает, можно с помощью скрипта testpso.mq5. Используемый им и прилагаемый к статье заголовочный файл ParticleSwarmParallel.mqh содержит, на самом деле, не только уже знакомые классы, но и много усовершенствований, которые будут описаны далее.
Тесты оформлены в ООП-стиле, что позволяет расширить их вашими любимыми целевыми функциями. Базу для тестов предоставляет класс BaseFunctor.
Все объекты производных классов будут автоматически регистрировать себя в момент создания с помощью метода register в классе PSOTests.
Сами тесты (оптимизация) запускаются методом run — он вызывает test для всех зарегистрированных объектов.
Существует множество популярных тестовых целевых функций. Среди них, в частности, есть «rosenbrock», «griewank», «sphere», которые и запрограммированы в скрипте. Например, для «сферы» мы можем определить область поиска и метод calculate следующим образом.
Следует отметить, что стандартные целевые функции подразумевают минимизацию, в то время как мы реализовали алгоритм в расчете на максимизацию (поскольку предполагается искать максимальную производительность эксперта). В связи с этим требуется брать результат вычисления со знаком минус. Также здесь пока не используется дискретный шаг, т.е. функции — непрерывные.
Запустив скрипт, можно убедиться, что в лог выводятся значения координат, приближенные к точному решению (экстремуму). Поскольку для частиц выполняется случайная инициализация, каждый запуск будет давать слегка отличающиеся значения. Точность решения зависит от входных параметров алгоритма.
Обратите внимание, что размер роя и количество групп (пишутся в лог в строках вида PSO[N] created: X/G, где N — размерность пространства, X — количество частиц, G — количество групп) автоматически выбираются по запрограммированным эмпирическим правилам на основе входных данных.
Переходим в параллельный мир
Наш первый тест всем хорош, за исключением одного нюанса — цикл пересчета частиц выполняется в одном единственном потоке, хотя терминал позволяет загрузить все ядра процессора. Напомним, что конечной целью является написание движка оптимизации методом PSO, способного встраиваться в эксперты для многопоточной оптимизации в тестере MetaTrader, и тем самым предоставляющего некую альтернативу стандартному генетическому алгоритму.
Разумеется, механический перенос кода алгоритма внутрь эксперта вместо скрипта не позволит распараллелить вычисления. Для этой цели требуется модифицировать сам алгоритм.
Если взглянуть на имеющийся код в контексте поставленной задачи, в параллельные расчеты напрашивается выделить группы частиц. Каждая группа может обрабатываться независимо от других. Внутри каждой группы выполняется полный цикл указанное количество раз.
Чтобы не переделывать ядро класса Swarm, воспользуемся простым приемом: вместо нескольких групп внутри класса предположим создавать несколько экземпляров данного класса, в каждом из которых количество групп будет вырожденным, то есть равным единице. Но эту конструкцию потребуется дополнить неким кодом, который позволил бы экземплярам обмениваться информацией между собой — ведь каждый экземпляр будет выполняться на своем агенте тестирования.
Сперва дополним инициализацию объектов новым способом.
Отталкиваясь от признака работы программы в режиме оптимизации, задаем количество групп равным 1. Размер роя по умолчанию определяется по эмпирическому правилу (если явно не задано отличное от 0 значение в параметре size).
В обработчике события OnTester эксперт сможет получить результат работы мини-роя (состоящего из единственной группы) с помощью функции getSolution и отправить его фреймом в терминал. Тот может анализировать проходы и выбирать лучший из них. Количество параллельных роев/групп имеет смысл делать равным как минимум количеству ядер, но может быть и больше (при этом желательно сохранять кратность количеству ядер). Разумеется, чем больше размерность пространства поиска оптимума, тем больше групп может потребоваться, но для простых тестов достаточно ограничиться количеством ядер.
Обмен данными между экземплярами требуется для того, чтобы обсчитывать пространство без дублирующихся точек. Как мы помним, в каждом объекте перечень обработанных точек хранится в бинарном дереве index. Мы могли бы отправлять его в терминал внутри фрейма по аналогии с результатами, но проблема заключается в том, что гипотетический объединенный реестр этих перечней нельзя обратно разослать по агентам. К сожалению, архитектура тестера поддерживает во время оптимизации управляемую пересылку данных только с агентов в терминал, но не наоборот. С терминала на агенты раздаются задания в закрытом формате.
Поэтому было принято решение ограничиться локальными агентами и сохранять index-ы каждой группы в файлы в общей папке (FILE_COMMON). При данном подходе каждый агент пишет свой index и имеет возможность в любой момент прочитать index-ы всех остальных проходов и пополнить ими свой index. В частности, это имеет смысл делать при инициализации прохода.
В MQL изменения в записываемом файле могут быть прочитаны другими процессами только после закрытия файла. Флаги FILE_SHARE_READ, FILE_SHARE_WRITE, а также функция FileFlush здесь не помогают.
Поддержка записи index-ов реализована с использованием известного паттерна «визитор».
Его минималистский интерфейс декларирует, что мы собираемся выполнить какую-то произвольную операцию над переданным узлом дерева. Для работы с файлами создана конкретная реализация-наследник — Exporter. Внутреннее значение каждого узла сохраняется на отдельной строке файла, в порядке обхода всего дерева по ссылкам.
Упорядоченный способ обхода дерева, кажущийся самым логичным, можно использовать только в целях отладки, если требуется получить отсортированные строки внутри файлов для их контекстного сравнения. Этот способ обложен директивой условной компиляции PSO_DEBUG_BINTREE и по умолчанию отключен. На практике, как уже было сказано, статистическую сбалансированность дереву обеспечивает факт добавления случайных, равномерно распределенных значений, хранимых в дереве (хэшей). Если же сохранить элементы дерева в отсортированном виде, то его последующая загрузка из файла приведет к максимально неоптимальной, медленной конфигурации (одна длинная ветка, фактически список). Чтобы этого избежать, на стадии сохранения дерева вносится элемент неопределенности в то, в какой последовательности будут обработаны узлы.
С помощью класса Explorer легко добавить в класс BinaryTree специальный метод, выполняющий сохранение дерева в переданный «визитёр».
Чтобы запустить операцию, требуется также новый метод в классе Swarm.
Параметр id — уникальный номер прохода (он же номер группы), именно по этому параметру мы будем настраивать оптимизацию в тестере. Вызывать метод exportIndex имеет смысл сразу после отработки двух методов роя: optimize и getSolution. Эта обязанность возложена на вызывающий код, потому что может требоваться не всегда — наш первый «параллельный» пример (см. далее) обойдется без неё. По определению, если количество групп равно числу ядер, они не успеют обменяться никакой информацией, поскольку будут запущены параллельно, а считывать файл внутри цикла — неэффективно.
Вспомогательная функция sharedName, упомянутая внутри exportIndex, позволяет создать уникальное имя на основе номера группы, названия эксперта и папки терминала.
Каждый найденный файл передается на обработку новому классу FileReader. Он ответственен за открытие файла в режиме чтения и последовательной загрузке всех строк, с их немедленной передачей в интерфейс Feed.
Как не трудно догадаться, интерфейс Feed должен быть реализован в самом рое, ведь мы передали внутрь FileReader-а this.
С помощью переменных _read, _unique и _restored метод подсчитывает, соответственно, общее число прочитанных элементов (из всех файлов), сколько было добавлено в index, и сколько среди тех, которые не были добавлены (то есть уже имеются в индексе), уникальных. Поскольку группы работают независимо, может оказаться, что в индексах разных групп есть дубликаты.
Эта статистика важна для определения момента, когда пространство поиска полностью исследовано или близко к этому. В этом случае количество _unique приближается к числу возможных комбинаций параметров.
По мере увеличения количества завершенных проходов в локальные индексы будет загружаться всё больше и больше уникальных точек из совместной истории. После очередного выполнения calculate индекс будет пополняться новыми проверенными точками, и сохраняемые файлы будут постоянно расти в размерах. Постепенно пересечения элементов в файлах станут преобладать. Это означает некоторые накладные расходы, но они в любом случае будут меньше, чем повторные расчеты торговой активности эксперта. Это отразится на ускорении циклов PSO по мере обработки каждой из последующих групп (заданий тестера) по мере приближения к полному покрытию пространства оптимизации.
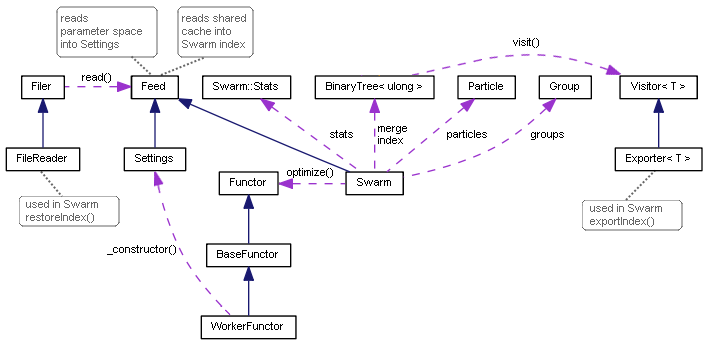
Диаграмма классов Particle Swarm Optimization
Тестирование параллельных вычислений
Для проверки работоспособности алгоритма в нескольких потоках преобразуем прежний скрипт в эксперт PPSO.mq5. Он будет запускаться в режиме математических вычислений, так как торговое окружение пока не нужно.
Набор тестовых целевых функций останется прежним, и классы их реализующие — практически без изменений. Выбор конкретного теста будет делаться во входных переменных.
Здесь же можно указать количество циклов, размер роя и количество групп. Все это используется в реализации функтора, в частности, конструкторе Swarm. Нулевые значения по умолчанию означают, как и прежде, автоподбор исходя из размерности задачи.
Все вычисления запускаются из обработчика OnTester. Параметр GroupCount (по которому будут организованы итерации тестера) используется в качестве рандомизатора, чтобы экземпляры в разных потоках содержали разные частицы. В зависимости от параметра TestCase создается тот или иной тестовый функтор. Далее вызывается метод functor.test(), после чего результаты можно прочитать с помощью functor.getSolution() и отправить фреймом в терминал.
В самом терминале работает связка функций OnTesterInit, OnTesterPass, OnTesterDeinit, которая собирает фреймы, попутно определяя наилучшее решение из присланных.
В лог пишется счетчик прохода, его порядковый номер (могут отличаться на сложных задачах, когда один поток обгоняет другой из-за различий в данных), значение целевой функции и соответствующие ему параметры. Окончательное решение выводится в OnTesterDeinit.
Предусмотрим также, чтобы эксперт можно было запускать не только в тестере, но и на обычном чарте. В таком случае алгоритм PSO отработает в штатном однопоточном режиме.
Посмотрим, как это работает. Выберем конкретные значения входных параметров:
При размещении эксперта на чарте получим примерно следующий лог.
Поскольку тестовые примеры считаются довольно быстро (в пределах секунды-двух), производить замеры времени не имеет смысла. Для реальных торговых задач мы это сделаем позднее.
Теперь выберем эксперт в тестере, в списке «Моделирование» установим «Математические вычисления», параметры эксперта оставим такими же как выше за исключением GroupCount. По этому параметру будет проводиться оптимизация, поэтому начальное и конечное значения поставим, например, соответственно 0 и 3, с шагом 1, чтобы было обработано 4 группы (по числу ядер). Причем в этом случае все группы будут иметь размер 100 (SwarmSize, целиком весь рой). При достаточном количестве ядер процессора (если все группы работают параллельно на агентах), это не должно сказаться на быстродействии, но увеличит точность решения за счет дополнительных проверок пространства оптимизации. Получим примерно такой лог.
Таким образом, мы убедились, что алгоритм PSO стал доступен в своей параллельной модификации в тестере в режиме оптимизации. Но пока это был только тест, использующий «математические вычисления». Настало время адаптировать PSO для оптимизации экспертов в торговом окружении.
Виртуализация и оптимизация эксперта (MQL4 API в MetaTrader 5)
Для оптимизации экспертов с помощью движка PSO необходимо реализовать функторы, умеющие по набору входных параметров имитировать торговлю на истории и вести статистику её показателей.
Здесь возникает дилемма, с которой сталкиваются многие прикладные разработчики при написании собственного оптимизатора поверх и/или вместо штатного. А именно — каким образом обеспечить торговое окружение, в первую очередь, котировки, но также и состояние счета, включая архив сделок. Если использовать режим математических вычислений, то требуется каким-то образом подготавливать и затем передавать в эксперт (на агенты) соответствующие данные. При этом приходится разрабатывать промежуточный слой API, «прозрачно» эмулирующий многие торговые функции, чтобы позволить эксперту работать по аналогии с обычным режимом онлайн.
Чтобы этого не делать, было принято решение воспользоваться уже существующим решением для виртуальной торговли, созданном полностью на MQL и утилизирующем стандартные структуры исторических данных, в частности тики и бары. Речь идет о библиотеке Virtual (автор fxsaber). С помощью неё можно рассчитать виртуальный проход эксперта на доступной истории как онлайн (например, для периодической самооптимизации на чарте), так и в тестере. В последнем случае, разумеется, используется любой привычный тиковый режим («Все тики», «Каждый тик на основе реальных тиков») или даже «OHLC на M1» — для быстрой, но более грубой оценки системы (количество тиков ограничено 4-мя в минуту).
После включения заголовочного файла Virtual.mqh (скачивается вместе с необходимыми зависимостями) в код эксперта, легко организовать виртуальный тест с помощью следующих строк:
Всю работу выполняет статический метод VIRTUAL::Tester. В него потребуется передать предварительно заполненный массив тиков желаемого исторического периода и степени детализации, указатель на функцию OnTick (подойдет и стандартный обработчик, если в него зашита логика переключения с торговли онлайн на виртуальную), а также начальный депозит (это опционально; если он не указан, будет взят текущий баланс счета). Если разместить приведенный выше фрагмент в обработчике OnTester (как это будет у нас), можно передать начальный депозит тестера. Узнать результат виртуальной торговли можно, вызвав привычную функцию TesterStatistics, которая после подключения библиотеки оказывается, на самом деле, «перекрыта», как и многие другие функции MQL API (желающие могут заглянуть в исходный код). Данное «перекрытие» — достаточно умное, чтобы делегировать вызовы исходной функции ядра, там где идет реальная торговля. Обратите внимание, что при виртуальной торговле в библиотеке рассчитаются не все стандартные показатели из TesterStatistics.
Особенностью библиотеки является то, что она основывается на торговом API MetaTrader 4. Иными словами, она применима только к экспертам, которые используют в коде «старые» функции, хотя и написаны на MQL5. Они работают в среде MetaTrader 5 благодаря другой известной библиотеке того же автора — MT4Orders.
В качестве «подопытного кролика» выступит модификация эксперта ExprBot.mq5, который был изначально представлен в статье Вычисление математических выражений (Часть 2). Он как раз реализован с использованием MT4Orders. Новая версия под именем ExprBotPSO.mq5 прилагается к данной статье.
Эксперт использует движок парсеров для вычисления торговых сигналов на основе выражений. Чем это нам пригодиться, станет ясно чуть позже. Торговую стратегию оставим прежней — пересечение двух скользящих средних с учетом заданного порога расхождения. Напомним, как выглядели настройки вместе с выражениями для сигналов — они особо не требуют пояснений, т.к. говорят сами за себя:
Если у Вас возникают вопросы, каким образом, входные переменные подставляются в выражения и каким образом встроенные функции EMA интегрируются с соответствующим индикатором, рекомендуется ознакомиться с упомянутой статьей. Новый робот работает на тех же принципах, и мы его слегка усовершенствуем.
Обратите внимание, движок парсеров был обновлен до версии v1.1 и также прилагается. Его старая версия, если она была скачана ранее, не подойдёт.
Помимо входных параметров для сигналов, о которых нам еще придется обсудить один нюанс, в эксперт внесены параметры для управления виртуальным тестированием и алгоритмом PSO.
В режиме VirtualTester эксперт только собирает тики в OnTick в массив. Затем в OnTester библиотека Virtual ведет торговлю по этому массиву, вызывая тот же обработчик OnTick, но уже со специальным взведенным признаком, допускающим исполнение кода с виртуальными операциям.
Итак, для каждого инкрементируемого значения PSO_GroupCount на отдельном агенте выполняется цикл из PSO_Cycles пересчетов роя размером PSO_SwarmSize частиц. Итого, получается проверка для PSO_GroupCount * PSO_Cycles * PSO_SwarmSize = N точек в пространстве оптимизации. Каждая точка — виртуальный прогон торговой системы.
Для достижения лучших результатов потребуется методом проб и ошибок найти подходящие PSO-параметры. Задавшись общим числом тестов N, можно варьировать компоненты. За счет случайных попаданий в одни и те же точки (напомним, они хранятся в бинарном дереве в рое) окончательное количество тестов будет меньше N.
Обмен данными между агентами происходит только в момент пересылки очередного задания. Задания, которые выполняются параллельно, еще не видят результаты друг друга и также могут с некоторой вероятностью обсчитать несколько идентичных координат.
В эксперт ExprBotPSO, разумеется, были добавлены классы функторов, в целом похожие на те, что мы видели в предыдущих примерах. В частности, метод test ожидаемо создает экземпляр роя, выполняет в нем оптимизацию и сохраняет результаты в переменных-членах (optimum, result[]).
Однако здесь мы впервые видим, как используются методы restoreIndex и exportIndex, описанные в предыдущих разделах. Задачи оптимизации эксперта обычно требуют большого количества расчетов (параметров и групп, каждая группа — один проход тестера), так что между агентами потребуется обмениваться информацией.
Виртуальное тестирование эксперта осуществляется в методе calculate по заявленной схеме. А вот в инициализации пространства оптимизации участвует один новый класс Settings.
Дело в том, что для запуска оптимизации пользователь будет настраивать входные параметры эксперта привычным образом. Однако алгоритм роя использует тестер только как средство распараллеливания задач (за счет инкремента номера группы). Поэтому наш эксперт должен уметь прочитать настройки рабочих параметров для оптимизации, сохранить их во вспомогательный файл, передаваемый на каждый агент, сбросить эти настройки в тестере и назначить оптимизацию по номеру группы. Класс Settings как раз и предназначен для чтения настроек из вспомогательного файла. У нас это будет «имя_эксперта.mq5.csv», который должен быть подключен с помощью директивы.
С классом Settings предлагается ознакомиться самостоятельно. Он выполняет чтение CSV-файла построчно, подразумевая наличие в нем следующих столбцов:
Все они запоминаются во внутренних массивах и доступны через get-методы по имени или номеру. Метод isVoid() возвращает признак отсутствия настроек (файл не удалось прочитать, он пустой или неверного формата).
Запись настроек в файл производится в обработчике OnTesterInit (см. ниже).
Рекомендуется сразу вручную создать пустой файл «имя_эксперта.mq5.csv» в папке MQL5/Files. Если этого не сделать, возникнут проблемы с тем, чтобы запустить оптимизацию с первого раза.
К сожалению, при первом запуске тестер хоть и создает данный файл автоматически, но не отправляет на агенты, из-за чего инициализация эксперта на них завершается ошибкой INIT_PARAMETERS_INCORRECT. Повторный запуск также не отправит его, поскольку тестер, судя по всему, кэширует информацию о подключаемых ресурсах и не учитывает появившийся файл, пока пользователь не перевыберет эксперт в выпадающем списке настроек тестера. Только после этого данный файл начнет нормально обновляться и пересылаться на агенты. Так что проще создать его вручную заранее.
Поиском параметров, для которых включен флаг оптимизации, и сбросом этих флагов занимается дополнительная функция ResetOptimizableParam. Также в OnTesterInit мы запоминаем имена этих параметров с помощью библиотеки Expert (автор fxsaber), чтобы более наглядно впоследствии выводить результаты. Но библиотека потребовалась прежде всего потому, что для вызова стандартных функций ParameterGetRange/ParameterSetRange нужно знать имена заранее, а MQL API не позволяет получить список параметров. Вместе с тем хотелось сделать код наиболее универсальным: пригодным для вставки в произвольный эксперт без особых правок.
В обработчике OnInit, выполняемом уже на агенте, настройки считываются в глобальный объект Settings следующим образом.
Как мы увидим далее, этот объект передается в создаваемый объект WorkerFunctor в обработчике OnTester, внутри которого фактически и производятся все вычисления и оптимизация. Но для того чтобы начать вычисления, мы должны сперва собрать тики. Это происходит в обработчике OnTick.
Почему делается именно так, а не вызовом функции CopyTicksRange непосредственно в OnTester? Во-первых, данная функция работает только в потиковых режимах, а желательно иметь поддержку быстрого режима OHLC M1 (по 4 тика в минуту). Во-вторых, в режиме генерации тиков размер возвращаемого массива по каким-то причинам ограничен 131072 (при работе по реальным тикам такого ограничения нет).
Переменная OnTesterCalled изначально равна false и потому собирается история тиков. OnTesterCalled взводится в true позднее, как и следует из её названия — в OnTester, перед тем как запустить PSO. Тогда объект Swarm начнет в цикле вычислять функтор, в котором, как мы видели выше, вызывается VIRTUAL::Tester со ссылкой на тот же OnTick. Только теперь OnTesterCalled будет равен true и управление передастся не на блок сборки тиков, а на блок торговой логики. Про неё поговорим чуть ниже. В будущем, по мере развития библиотеки PSO возможно появление механизмов упрощения интеграции в существующие эксперты путем подмены обработчика OnTick в самом заголовочном файле библиотеки.
А сейчас — собственно OnTester (в упрощенном виде).
Здесь мы как раз видим создание функтора WorkerFunctor по набору параметров из объекта settings и запуск роя с помощью его метода test. Полученные результаты отправляются фреймом в терминал, где попадают в OnTesterPass.
Обработчик OnTesterPass аналогичен тому, что был в тестовом эксперте PPSO, только в нем получаемые во фреймах данные выводятся не в лог, а в CSV-файл с именем вида PPSO-название_эксперта-дата_время.
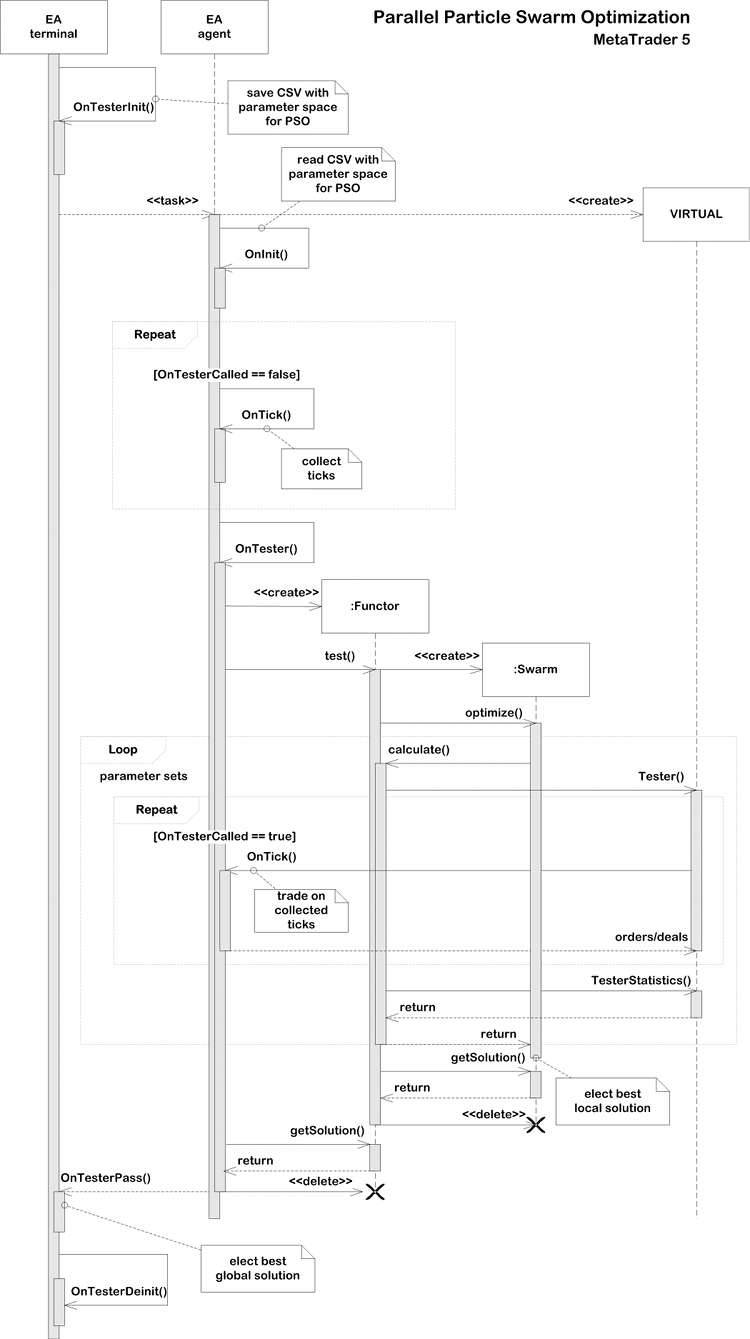
Диаграмма последовательности Parallel Particle Swarm Optimization
Вернемся наконец к торговой стратегии. По существу она осталась такой же как в упомянутой статье Вычисление математических выражений (Часть 2). Однако для виртуальной торговли необходимо внести некоторые коррективы. Прежние формулы для сигналов вычисляют индикаторы EMA по ценам открытия на нулевом баре:
Теперь же их следует считывать с исторических баров (ведь вычисления производятся в самом конце прохода, из OnTester). Узнать номер «текущего» бара в прошлом очень просто: библиотека Virtual перекрывает системную функцию TimeCurrent, и потому мы можем в OnTick написать:
Актуальный номер бара следует добавить под подходящим именем в таблицу переменных для выражений, например, «Bar», и тогда сигнальные формулы можно переписать так:
В обновленной версии парсеров изменение переменной (номера бара) и расчет с ней формулы делается с промежуточным вызовом нового метода with (также в OnTick):
Далее весь торговый код OnTick идет без изменений.
Но на этом необходимые исправления не заканчиваются.
Текущие приведенные формулы используют фиксированные периоды EMA, заданные в настройках и преобразуемые в переменные внутри выражений. Однако в процессе оптимизации эти периоды требуется менять, что означает разные экземпляры индикаторов. Но ведь виртуальная оптимизация с подстройкой параметров роем проходит _внутри_ прогона тестера, в самом его конце, в функции OnTester. Там уже поздно создавать хэндлы индикаторов.
Данная проблема носит глобальный характер для любой виртуальной оптимизации и имеет 3 наиболее очевидных решения:
Последний способ оставляет открытым вопрос с системами, которые рассчитывают сигналы в потиковом режиме. Дело в том, что в виртуальной истории все бары уже закрыты, и индикаторы уже построены. Иными словами, доступны только сигналы по барам. Если по такой истории «прогнать» систему без контроля открытия бара, она даст намного меньше сделок и они будут менее качественные, чем невиртуальный по тикам.
В нашем эксперте торговля ведется по барам, так что это не проблема. В некоторых примерах экспертов, поставляемых вместе с MetaTrader 5, это также имеет место, но следует обращать внимание, как именно детектируется событие открытия нового бара. Способ с контролем единичного тикового объема не подходит для виртуальной истории, потому что все бары уже заполнены тиками. Поэтому рекомендуется определять новый бар путем сравнения его времени с предыдущим известным.
Для решения описанной проблемы третьим способом был расширен движок выражений. В дополнение к функциям одиночных индикаторов MA (MAIndicatorFunc) созданы функции вееров MA (MultiMAIndicatorFunc, см. Indicators.mqh). Их имя должно начинаться с префикса «M_» и содержать минимальный период, шаг периода и максимальный период, например:
Способ расчета и тип цены указываются в имени как и прежде. Здесь в сигналах предписано создать веер EMA по цене OPEN с периодами от 9 до 27 (включительно), с шагом 6.
Еще одним новшеством в библиотеке выражений является набор переменных, обеспечивающих доступ к торговой статистике из TesterStatistics (см. TesterStats.mqh). На его основе появилась возможность добавить в эксперт входную переменную Formula для задания целевого показателя в виде произвольного выражения. Когда эта переменная заполнена, Estimator игнорируется. В частности, вместо STAT_PROFIT_FACTOR (который неопределен для нулевых убытков) в Estimator можно задать более «гладкий» показатель с похожей по смыслу формулой: «(GROSSPROFIT-(1/(TRADES+1)))/-(GROSSLOSS-1/(TRADES+1))».
Итак, все готово для запуска оптимизации виртуальной торговли методом PSO.
Проверка на практике
Подготовим тестер. Он должен использовать медленную оптимизацию, т.е. полный перебор параметров. В нашем случае она не будет медленной, потому что в каждом прогоне меняется только номер группы, а выборочный перебор рабочих параметров эксперта осуществляется роем внутри своего цикла. Использовать генетику нельзя по трем причинам. Во-первых, она не гарантирует обсчет всех комбинацией параметров (в нашем случае — заданного числа групп). Во-вторых, она в силу своей специфики будет постепенно «смещаться» в сторону тех параметров, которые дали более привлекательный результат, не учитывая тот факт, что нет зависимости между номером группы и её успехом — номер групп лишь выступает рандомизатором структуры данных PSO. В-третьих, количество групп обычно не такое большое, при котором включается генетика.
Оптимизацию проводим по максимуму пользовательского критерия.
Сперва оптимизируем эксперт штатным способом, с отключенной библиотекой Virtual (файл с настройками ExprBotPSO-standard-optimization.set). Количество комбинаций параметров для оптимизации выбрано небольшим в целях демонстрации. Параметры Fast и Slow меняются от 9 до 45 с шагом 6, параметр T — от 0 до 0.01 с шагом 0.0025.
EURUSD, H1, диапазон — с начала 2020 года, по реальным тикам. Получим примерно следующие результаты:
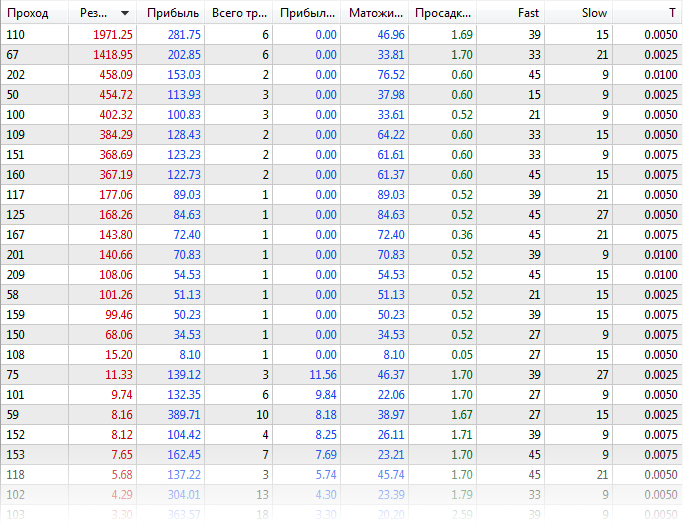
Таблица результатов штатной оптимизации
В логе посмотрим, сколько ушло времени на двух агентах — почти 21 минута.
Теперь оптимизируем эксперт с включенной виртуальной торговлей и PSO (ExprBotPSO-virtual-pso-optimization.set). Количество групп равное 4 определяется итерацией параметра PSO_GroupCount от 0 до 3. Прочие рабочие параметры, для которых включена оптимизация, будут принудительно отключены в штатной оптимизации, но переданы на агенты в CSV-файлах для внутренней виртуальной оптимизации алгоритмом PSO.
В моделировании оставим режим по реальным тикам, но также можно было использовать генерацию или OHLC M1 для быстрых расчетов. Математические вычисления не подойдут, так как для виртуальной торговли мы собираем в тестере тики.
В логе тестера получим примерно следующее:
Каждый pass — это теперь пакет виртуальных оптимизаций, поэтому он стал длиннее, но их в целом меньше, и общее время существенно сократилось — до 4-х минут.
В логе терминала получим сообщения из фреймов (лучшие показатели каждой группы). Правда показатели реальной и виртуальной торговли слегка отличаются.
Следует отметить, что результаты не будут точно совпадать (даже если бы у нас была потиковая безиндикаторная стратегия), потому что существуют нюансы работы тестера, которые невозможно повторить в MQL библиотеке. Вот лишь некоторые из них:
Более подробную информацию по библиотеке Virtual можно найти в её документации и обсуждениях.
В качестве отладки и для понимания процесса работы роя тестовый эксперт поддерживает режим виртуальной оптимизации на одном ядре внутри обычного прогона тестера. Пример настроек прилагается в файле ExprBotPSO-virtual-internal-optimization-single-pass.set. Не забудьте отключить оптимизацию в тестере.
В логе тестера при этом подробно пишутся промежуточные результаты. В каждом цикле из заданных PSO_Cycles выводится положение и значение целевой функции каждой частицы. Если частица попадает на уже проверенные координаты, расчет пропускается.
Поскольку пространство оптимизации небольшое, оно оказалось полностью покрыто к 19 циклу. Для реальных задач с миллионами комбинаций такого, разумеется, не произойдет. Для них очень важно методом проб и ошибок подобрать правильное сочетание PSO_Cycles, PSO_SwarmSize, PSO_GroupCount.
Не забудьте, что при PSO один проход тестера для каждой из PSO_GroupCount выполняет внутри вплоть до PSO_Cycles*PSO_SwarmSize виртуальных одиночных проходов, поэтому индикация прогресса будет существенно медленнее, чем обычно.
Многие трейдеры пытаются добиться от встроенной генетической оптимизации лучших результатов, запуская её много раз подряд — это собирает различные тесты в силу случайной инициализации, и после нескольких запусков есть шанс обнаружить прогресс. В случае PSO аналогом многократного запуска генетики выступает PSO_GroupCount. Количество одиночных прогонов, которое в генетике может достигать 10000, следует распределить в PSO между двумя составляющими произведения PSO_Cycles*PSO_SwarmSize, например, 100*100. PSO_Cycles выступает аналогом поколений в генетике, а PSO_SwarmSize — размером популяции.
Виртуализация экспертов MQL5 API
До сих пор мы изучали пример эксперта, написанного с использованием торгового API MQL4. Это вызвано особенностями реализации библиотеки Virtual. Вместе с тем хотелось бы применить PSO и для экспертов с «новыми» функциями MQL5 API. Для этой цели был разработан экспериментальный промежуточный слой переадресации вызовов MQL5 API в MQL4 API. Он оформлен в виде файла MT5Bridge.mqh, который требует для своей работы библиотеку Virtual и/или MT4Orders.
После добавления Virtual и MT5Bridge в начале кода, перед другими #include, обращение к функциям MQL5 API идет через переопределенные функции «моста», из которых вызываются «виртуальные» функции MQL4 API. В результате появляется возможность виртуально тестировать и оптимизировать эксперт. В частности, можно организовать оптимизацию PSO аналогично тому, как это было сделано в ExprBotPSO. Потребуется написать (частично скопировать) функтор и обработчики для тестера. Но самым трудоемким может оказаться адаптация генерирования сигналов от индикаторов для переменных параметров.
Экспериментальный статус MT5Bridge.mqh означает, что его работоспособность широко не проверялась. Это исследование из разряда Proof Of the Concept. Используйте исходный код для отладки и исправления ошибок.
Заключение
Мы рассмотрели алгоритм оптимизации методом роя частиц и реализовали его на MQL с поддержкой многопоточной работы на агентах тестера. Наличие открытых настроек PSO позволяет более гибко регулировать процесс, чем при использовании встроенной генетической оптимизации. Помимо настроек, вынесенных сейчас во входные параметры, имеет смысл «поиграть» и другими адаптируемыми коэффициентами, которые пока использовались как аргументы метода optimize со значениями по умолчанию: inertia(0.8), selfBoost(0.4), groupBoost(0.4). Это несомненно придаст гибкости алгоритму, но и затруднит подбор настроек для конкретной задачи. Прилагаемую библиотеку PSO можно использовать как в режиме математических вычислений (если у Вас проработан собственный механизм виртуальных котировок, индикаторов и сделок), так и в тиково-баровых режимах с привлечением сторонних готовых классов эмулирования торговли, таких как Virtual.



